 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Semantics Survive the Connector? Diagnosing VLM-to-DiT Alignment in Video Editing
May 20, 2026Flow matching based video generative models have been increasingly relying on prepended Vision-Language Models (VLMs) to handle complex, instruction-based video editing. The prevailing assumption underlying this paradigm is that a connector module can seamlessly align the VLM's rich multi-modal reasoning with the original text embedding space of DiTs. However, we hypothesize that this alignment acts as a severe semantic bottleneck, degrading fine-grained structural variables. Verifying this is challenging, as end-to-end evaluations conflate alignment failures with generation errors, and natural datasets lack disentangled annotations. To rigorously investigate this, we propose a controlled data processing pipeline based on video composition that results in TRACE-Edit, a diagnostic dataset focusing on relation-based editing. Leveraging this dataset, we propose a comprehensive diagnostic protocol to analyze two important designs of meta-query and connector in the existing video editing models. Systematic evaluation of four representative model cases reveals that fine-grained structural semantics can be severely degraded during alignment. Our findings overturn the assumption of lossless semantic transfer, identifying the VLM-to-DiT alignment as a major bottleneck and providing a new diagnostic foundation for future multi-modal alignment architectures.
PixVerve: Advancing Native UHR Image Generation to 100MP with a Large-Scale High-Quality Dataset
May 19, 2026Text-to-Image (T2I) models have recently seen notable progress around 1K and 2K resolution. With the extreme desire for better visual experience and the rapid development of imaging technology, the demand for Ultra-High-Resolution (UHR) image generation has grown significantly. However, UHR image generation poses great challenges due to the scarcity and complexity of high-resolution content. In this paper, we first introduce PixVerve-95K, a high-quality, open-source UHR T2I dataset curated with a carefully designed data pipeline, which contains 95K images across diverse scenarios (each image has a minimum pixel-count of 100M) and seven-dimensional annotations. Based on our large-scale image-text dataset, we take a pioneering step to extend various T2I foundation models to native 100MP generation with three training schemes. Finally, leveraging both conventional metrics and multimodal large language model-based assessments, our proposed PixVerve-Bench benchmark establishes a comprehensive evaluation protocol for UHR images encompassing visual quality and semantic alignment. Extensive experimental results on our benchmark and the constructive exploration of training strategies collaboratively provide valuable insights for future breakthroughs.
Evolution of Optimization Methods: Algorithms, Scenarios, and Evaluations
Apr 14, 2026Balancing convergence speed, generalization capability, and computational efficiency remains a core challenge in deep learning optimization. First-order gradient descent methods, epitomized by stochastic gradient descent (SGD) and Adam, serve as the cornerstone of modern training pipelines. However, large-scale model training, stringent differential privacy requirements, and distributed learning paradigms expose critical limitations in these conventional approaches regarding privacy protection and memory efficiency. To mitigate these bottlenecks, researchers explore second-order optimization techniques to surpass first-order performance ceilings, while zeroth-order methods reemerge to alleviate memory constraints inherent to large-scale training. Despite this proliferation of methodologies, the field lacks a cohesive framework that unifies underlying principles and delineates application scenarios for these disparate approaches. In this work, we retrospectively analyze the evolutionary trajectory of deep learning optimization algorithms and present a comprehensive empirical evaluation of mainstream optimizers across diverse model architectures and training scenarios. We distill key emerging trends and fundamental design trade-offs, pinpointing promising directions for future research. By synthesizing theoretical insights with extensive empirical evidence, we provide actionable guidance for designing next-generation highly efficient, robust, and trustworthy optimization methods. The code is available at https://github.com/APRIL-AIGC/Awesome-Optimizer.
The Latent Space: Foundation, Evolution, Mechanism, Ability, and Outlook
Apr 02, 2026Latent space is rapidly emerging as a native substrate for language-based models. While modern systems are still commonly understood through explicit token-level generation, an increasing body of work shows that many critical internal processes are more naturally carried out in continuous latent space than in human-readable verbal traces. This shift is driven by the structural limitations of explicit-space computation, including linguistic redundancy, discretization bottlenecks, sequential inefficiency, and semantic loss. This survey aims to provide a unified and up-to-date landscape of latent space in language-based models. We organize the survey into five sequential perspectives: Foundation, Evolution, Mechanism, Ability, and Outlook. We begin by delineating the scope of latent space, distinguishing it from explicit or verbal space and from the latent spaces commonly studied in generative visual models. We then trace the field's evolution from early exploratory efforts to the current large-scale expansion. To organize the technical landscape, we examine existing work through the complementary lenses of mechanism and ability. From the perspective of Mechanism, we identify four major lines of development: Architecture, Representation, Computation, and Optimization. From the perspective of Ability, we show how latent space supports a broad capability spectrum spanning Reasoning, Planning, Modeling, Perception, Memory, Collaboration, and Embodiment. Beyond consolidation, we discuss the key open challenges, and outline promising directions for future research. We hope this survey serves not only as a reference for existing work, but also as a foundation for understanding latent space as a general computational and systems paradigm for next-generation intelligence.
Dual Latent Memory for Visual Multi-agent System
Jan 31, 2026While Visual Multi-Agent Systems (VMAS) promise to enhance comprehensive abilities through inter-agent collaboration, empirical evidence reveals a counter-intuitive "scaling wall": increasing agent turns often degrades performance while exponentially inflating token costs. We attribute this failure to the information bottleneck inherent in text-centric communication, where converting perceptual and thinking trajectories into discrete natural language inevitably induces semantic loss. To this end, we propose L$^{2}$-VMAS, a novel model-agnostic framework that enables inter-agent collaboration with dual latent memories. Furthermore, we decouple the perception and thinking while dynamically synthesizing dual latent memories. Additionally, we introduce an entropy-driven proactive triggering that replaces passive information transmission with efficient, on-demand memory access. Extensive experiments among backbones, sizes, and multi-agent structures demonstrate that our method effectively breaks the "scaling wall" with superb scalability, improving average accuracy by 2.7-5.4% while reducing token usage by 21.3-44.8%. Codes: https://github.com/YU-deep/L2-VMAS.
FFP-300K: Scaling First-Frame Propagation for Generalizable Video Editing
Jan 06, 2026First-Frame Propagation (FFP) offers a promising paradigm for controllable video editing, but existing methods are hampered by a reliance on cumbersome run-time guidance. We identify the root cause of this limitation as the inadequacy of current training datasets, which are often too short, low-resolution, and lack the task diversity required to teach robust temporal priors. To address this foundational data gap, we first introduce FFP-300K, a new large-scale dataset comprising 300K high-fidelity video pairs at 720p resolution and 81 frames in length, constructed via a principled two-track pipeline for diverse local and global edits. Building on this dataset, we propose a novel framework designed for true guidance-free FFP that resolves the critical tension between maintaining first-frame appearance and preserving source video motion. Architecturally, we introduce Adaptive Spatio-Temporal RoPE (AST-RoPE), which dynamically remaps positional encodings to disentangle appearance and motion references. At the objective level, we employ a self-distillation strategy where an identity propagation task acts as a powerful regularizer, ensuring long-term temporal stability and preventing semantic drift. Comprehensive experiments on the EditVerseBench benchmark demonstrate that our method significantly outperforming existing academic and commercial models by receiving about 0.2 PickScore and 0.3 VLM score improvement against these competitors.
LongVie 2: Multimodal Controllable Ultra-Long Video World Model
Dec 15, 2025Building video world models upon pretrained video generation systems represents an important yet challenging step toward general spatiotemporal intelligence. A world model should possess three essential properties: controllability, long-term visual quality, and temporal consistency. To this end, we take a progressive approach-first enhancing controllability and then extending toward long-term, high-quality generation. We present LongVie 2, an end-to-end autoregressive framework trained in three stages: (1) Multi-modal guidance, which integrates dense and sparse control signals to provide implicit world-level supervision and improve controllability; (2) Degradation-aware training on the input frame, bridging the gap between training and long-term inference to maintain high visual quality; and (3) History-context guidance, which aligns contextual information across adjacent clips to ensure temporal consistency. We further introduce LongVGenBench, a comprehensive benchmark comprising 100 high-resolution one-minute videos covering diverse real-world and synthetic environments. Extensive experiments demonstrate that LongVie 2 achieves state-of-the-art performance in long-range controllability, temporal coherence, and visual fidelity, and supports continuous video generation lasting up to five minutes, marking a significant step toward unified video world modeling.
VisMem: Latent Vision Memory Unlocks Potential of Vision-Language Models
Nov 14, 2025Despite the remarkable success of Vision-Language Models (VLMs), their performance on a range of complex visual tasks is often hindered by a "visual processing bottleneck": a propensity to lose grounding in visual evidence and exhibit a deficit in contextualized visual experience during prolonged generation. Drawing inspiration from human cognitive memory theory, which distinguishes short-term visually-dominant memory and long-term semantically-dominant memory, we propose VisMem, a cognitively-aligned framework that equips VLMs with dynamic latent vision memories, a short-term module for fine-grained perceptual retention and a long-term module for abstract semantic consolidation. These memories are seamlessly invoked during inference, allowing VLMs to maintain both perceptual fidelity and semantic consistency across thinking and generation. Extensive experiments across diverse visual benchmarks for understanding, reasoning, and generation reveal that VisMem delivers a significant average performance boost of 11.8% relative to the vanilla model and outperforms all counterparts, establishing a new paradigm for latent-space memory enhancement. The code will be available: https://github.com/YU-deep/VisMem.git.
SwiftVideo: A Unified Framework for Few-Step Video Generation through Trajectory-Distribution Alignment
Aug 08, 2025Diffusion-based or flow-based models have achieved significant progress in video synthesis but require multiple iterative sampling steps, which incurs substantial computational overhead. While many distillation methods that are solely based on trajectory-preserving or distribution-matching have been developed to accelerate video generation models, these approaches often suffer from performance breakdown or increased artifacts under few-step settings. To address these limitations, we propose \textbf{\emph{SwiftVideo}}, a unified and stable distillation framework that combines the advantages of trajectory-preserving and distribution-matching strategies. Our approach introduces continuous-time consistency distillation to ensure precise preservation of ODE trajectories. Subsequently, we propose a dual-perspective alignment that includes distribution alignment between synthetic and real data along with trajectory alignment across different inference steps. Our method maintains high-quality video generation while substantially reducing the number of inference steps. Quantitative evaluations on the OpenVid-1M benchmark demonstrate that our method significantly outperforms existing approaches in few-step video generation.
Transferable Adversarial Attacks on Black-Box Vision-Language Models
May 02, 2025
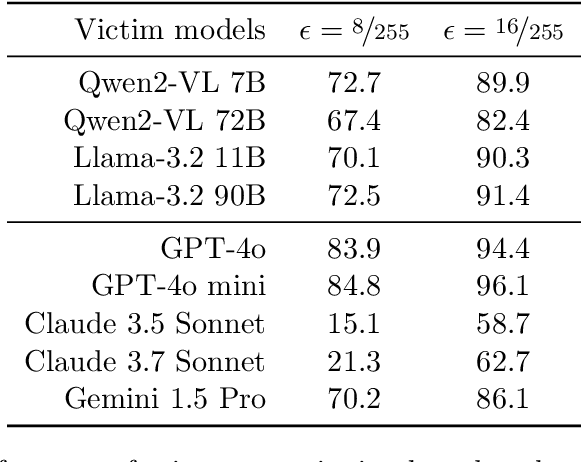
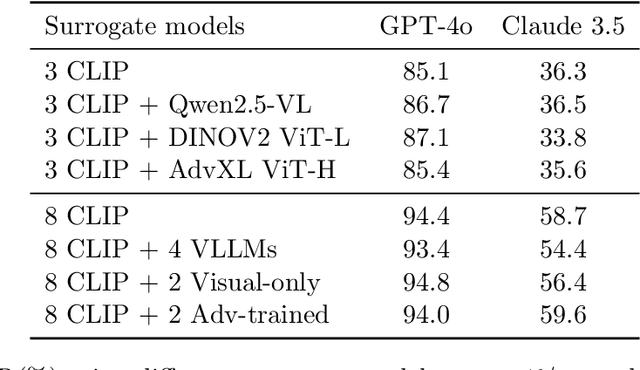
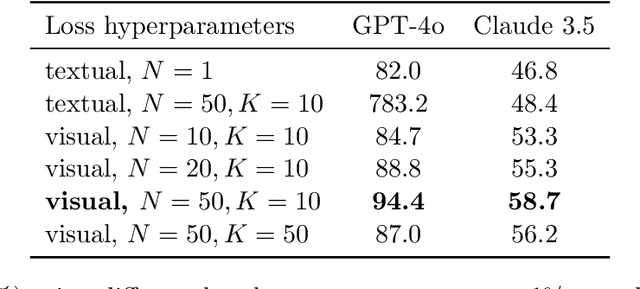
Vision Large Language Models (VLLMs) are increasingly deployed to offer advanced capabilities on inputs comprising both text and images. While prior research has shown that adversarial attacks can transfer from open-source to proprietary black-box models in text-only and vision-only contexts, the extent and effectiveness of such vulnerabilities remain underexplored for VLLMs. We present a comprehensive analysis demonstrating that targeted adversarial examples are highly transferable to widely-used proprietary VLLMs such as GPT-4o, Claude, and Gemini. We show that attackers can craft perturbations to induce specific attacker-chosen interpretations of visual information, such as misinterpreting hazardous content as safe, overlooking sensitive or restricted material, or generating detailed incorrect responses aligned with the attacker's intent. Furthermore, we discover that universal perturbations -- modifications applicable to a wide set of images -- can consistently induce these misinterpretations across multiple proprietary VLLMs. Our experimental results on object recognition, visual question answering, and image captioning show that this vulnerability is common across current state-of-the-art models, and underscore an urgent need for robust mitigations to ensure the safe and secure deployment of VLLMs.